这篇文章是自动驾驶领域的文章,自动驾驶领域往往有两类任务:感知环境(如:语义分割),驾驶决策(根据周围环境做出相应的操作)。
这篇文章聚焦于自动驾驶中的点对点的导航问题,将多任务学习引入了自动驾驶,并且引入了注意力机制有效提高了准确率,文末也通过可视化图热图对注意力机制进行了定性的分析。本文的模型能够识别红绿灯(以往的模型做不到)。
这篇文章是基于RGB单目相机,并且是端到端的,采用了CIL框架。(端到端指的是输入是原始数据,输出是最后的结果,原来输入端不是直接的原始数据,而是在原始数据中提取的特征)
个人认为这篇文章最大的创新点就是利用注意力机制在一个encoder上得到了两个type(对应与上面提到的自动驾驶的两类任务),然后在两个type后面接不同的解码器做不同的任务。
CBAM
文章中用到了CBAM模块,首先对它进行一个介绍。
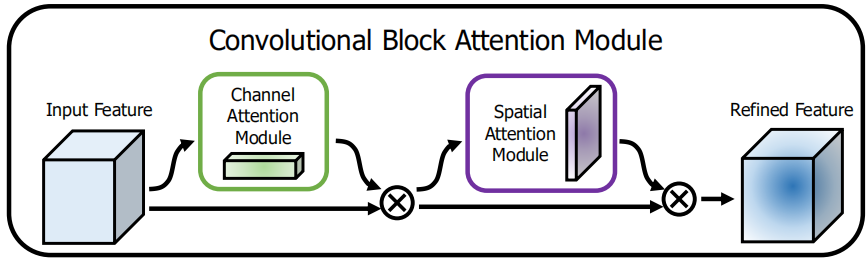
卷积块注意模块(CBAM)融合了通道注意力机制和空间注意力机制。采用模块化的设计,几乎可以没有开销地嵌入任何网络。
总体的结构如下图,它首先做通道注意力,再做空间注意力
通道注意力模块
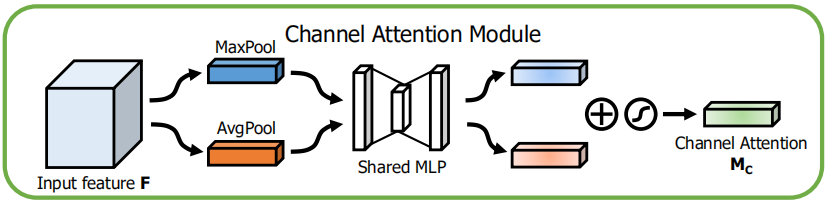
- 首先在每个通道上做最大池化和平均池化
- 分别将两个向量输入一个全连接的网络,输出要与输入向量的长度保持一致
- 将两个向量相加,经过Sigmoid函数。得到的向量表示每个通道对应的权重。
- 将向量与输入的特征图的每个对应的通道相乘
空间注意力模块
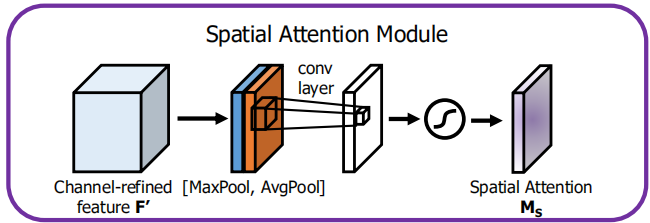
- 沿着通道做最大池化和平均池化。以最大池化为例:就是在所有通道的对应像素点中取一个最大值。得到两个二维的特征图。
- 将两个特征图沿着通道拼起来,通过一个卷积层,文章中是7*7的卷积,得到一个二维的特征图。
- 经过Sigmoid函数,得到的是特征图中每个像素点对应的权重。
- 将权重图与输入图中对应位置相乘。
ResNet引入CBAM
- CBAM并不会影响原来的网络结构
- CBAM加在残差连接之前
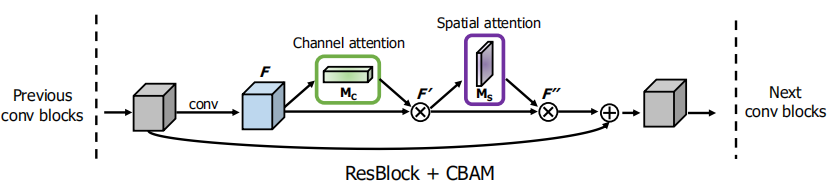
网络结构
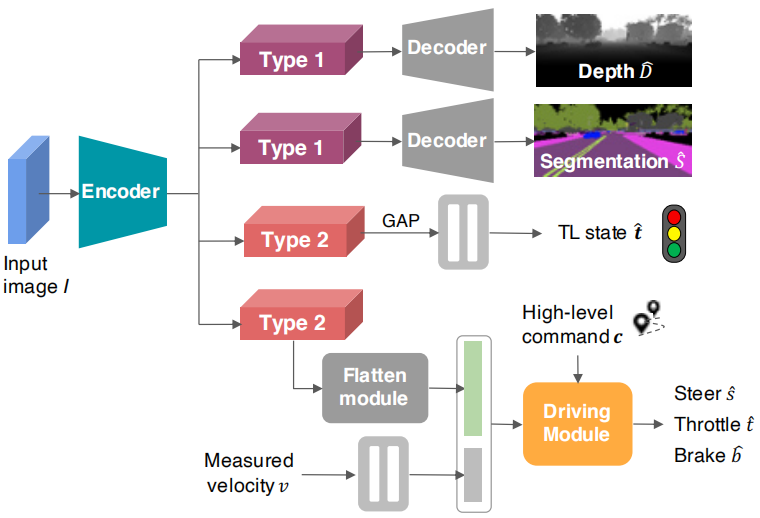
Encoder
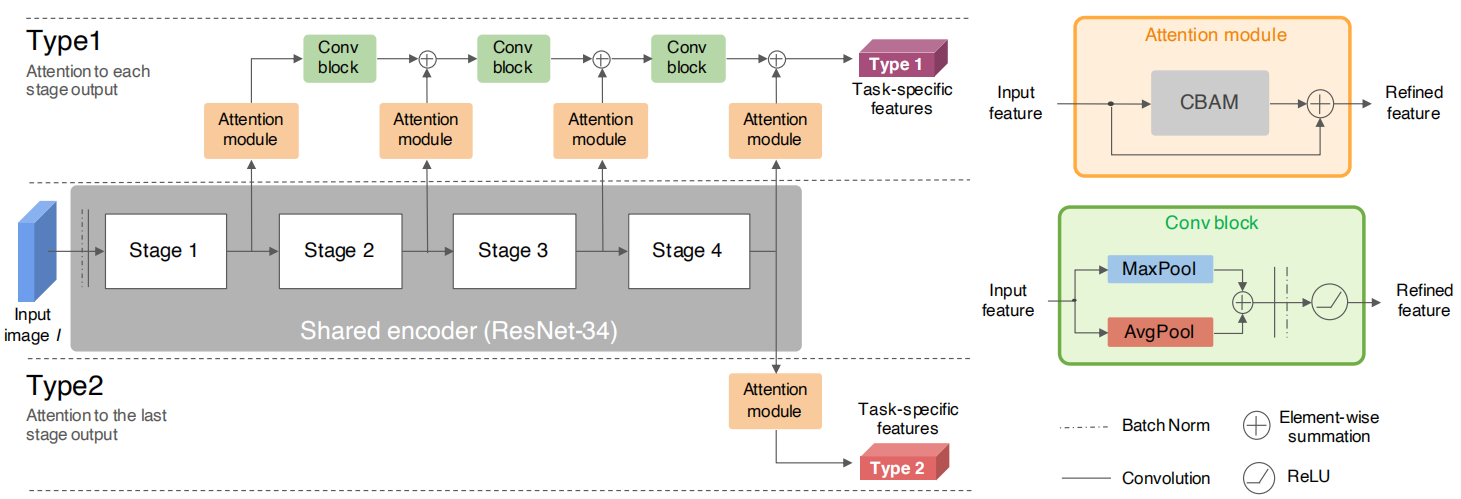
主干网络采用了ResNet-34,引申出了两种type。type1后续会接上decoder用于处理语义分割,深度预测的任务。type2会去处理信号灯分类和控制预测。作者也对这种操作做了简单的说明,因为语义分割和深度预测往往需要更高分辨率的特征图以免丢失细节,而信号灯分类和控制预测需要隐藏抽象特征。
注意这里的Conv Block,经过池化以后通道数是不变的,为了能与下一层的特征图相加,接上了一个卷积来使通道数翻倍。
Decoder
这一部分文章写得有点坑,图中两个decoder的结构参考了一篇论文,然而那篇论文又参考了另一篇论文o(╥﹏╥)o。然而,我读了两篇论文后,发现这里的结构不可能完全与它们一致。所以实际结构怎么样只有看了源码才知道。不过这并不影响理解这部分。
实际上简单思考也知道,由于decoder的输出和网络的输入图像是一样大小的。因此,这里的decoder肯定是用了几个上采样调整到与原图一样的尺寸,最后接上一个softmax。
作者也说了,经过实验发现,当segmentation的decoder深度大于depth的decoder深度时,模型的整体效果比较好。
信号灯分类
分为四类:红,黄,绿,无信号灯。对采集到的每一帧都给出一个分类
应该就是连个全连接层。
驾驶模块
这里会有两个额外的输入信息,分别是车辆的速度v和更高级别的命令c(如左转)。type2 的特征图展开成一个向量。
驾驶模块中接了四个不同的头,分别对应于4中不同的高级命令(车道保持,左转,右转,直行)。根据输入的高级命令c,选择不同的头输出操作指令。这种多头的结构要好于单头(之前的论文证明过)。
说明:车辆在面对十字路口中,往往可以有多个指令的选择,这会引起歧义。CIL框架为了解决这个问题会给出一个高级命令(如左转)。然后模型根据这个命令给出更加基础的操作(踩油门,踩刹车,转方向盘)。这个高级指令在这篇文章中是使用A*算法做路径规划给出的。它对没一帧的画面都会给出一个c指示下一步前进的方向。
损失函数
\[ L_{total}=\lambda _{control}L_{control}+\lambda _{tl}L_{tl}+\lambda _{seg}L_{seg}+\lambda _{dep}L_{dep} \\ L_{control}=\sum_{c=1}^3{\gamma _cL_c} \]
\(L_{control}\)和\(L_{dep}\)采用均方差损失,\(L_{tl}\)和\(L_{seg}\)采用交叉熵损失。
第二个式子中c=1代表转向,c=2代表油门,c=3代表刹车
\(\lambda\)和\(\gamma\)凭经验设置。
实验
数据集增强和数据集均衡
为了扩充数据集,作者做了数据集增强。
采集到的数据集是不平衡的(直线行驶特别多),于是文章采用降采样的方法,让直线行驶选中的概率降低。实测下来数据集均衡对于模型非常重要。
实验结果看看table就明白了。



