本文基于机器人场景,提出了一种multi-DDPG的算法,将DDPG拓展到了多任务场景,使机器人能够学习多个连续的动作。并且引入mlpconv显著减少了模型参数量,将图像和传感器数据组合为输入。
MLPConv
mlpconv
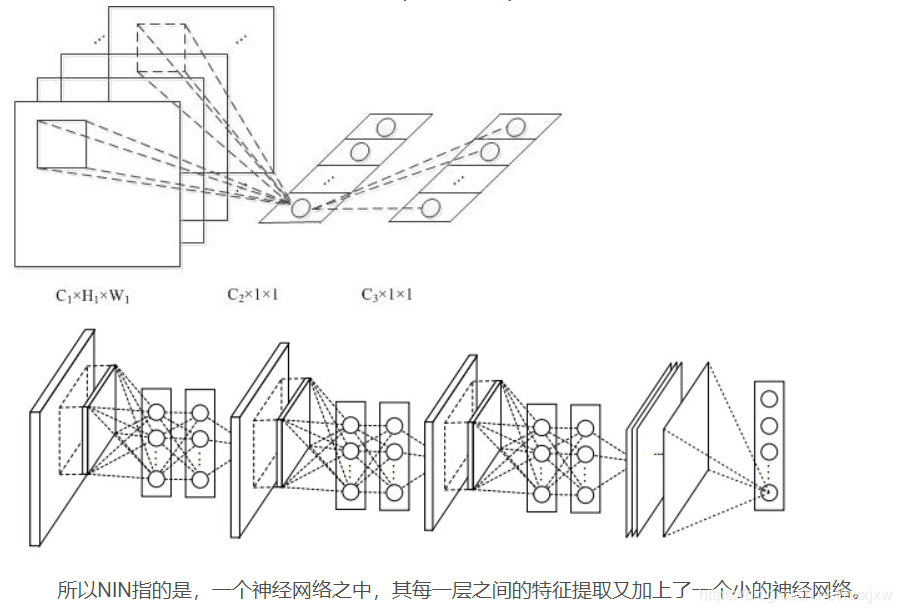
一般卷积操作可以看成特征的提取操作,而一般卷积一层只相当于一个线性操作,所以其只能提取出线性特征。所以作者就想能否在卷积层后也加入一个MLP使得每层卷积操作能够提取非线性特征。而为了减少参数量,又用1*1的卷积层模拟了MLP
一个mlpconv卷积块是1个卷积后加两个1*1的卷积,但是每个1*1卷积后面都跟着一个ReLu, 所以可以引入更多的非线性。
这里的图画的是真的坑,这里的\(C_2\)指的是1*1卷积核的数量,展开的这一个长条形的向量指的是同一个位置的像素在经过\(C_2\)个卷积过后的值。中间的类似全连接的部分指的是1*1卷积,因为对同一个像素点施加不同的1*1卷积就类似于全连接的结构。也就是相当于在不同通道之间进行全连接,==而不是把特征图展平。==
全局平均池化
mlpconv还提出了全局平均池化的概念。
Global Average Pooling主要为了解决全连接层参数过多的问题,早期对于分类问题,最后一个卷积层的 Feature Map 通常与全连接层连接,最后通过 softmax 逻辑回归分类。全连接层带来的问题就是参数空间过大,容易过拟合
global average pooling的概念非常简单,分类任务有多少个类别,就控制最终产生多少个feature map,也就是多少通道数。然后对于整个特征图做平均池化。就得到与通道数相等的类别数。
Multi-DDPG
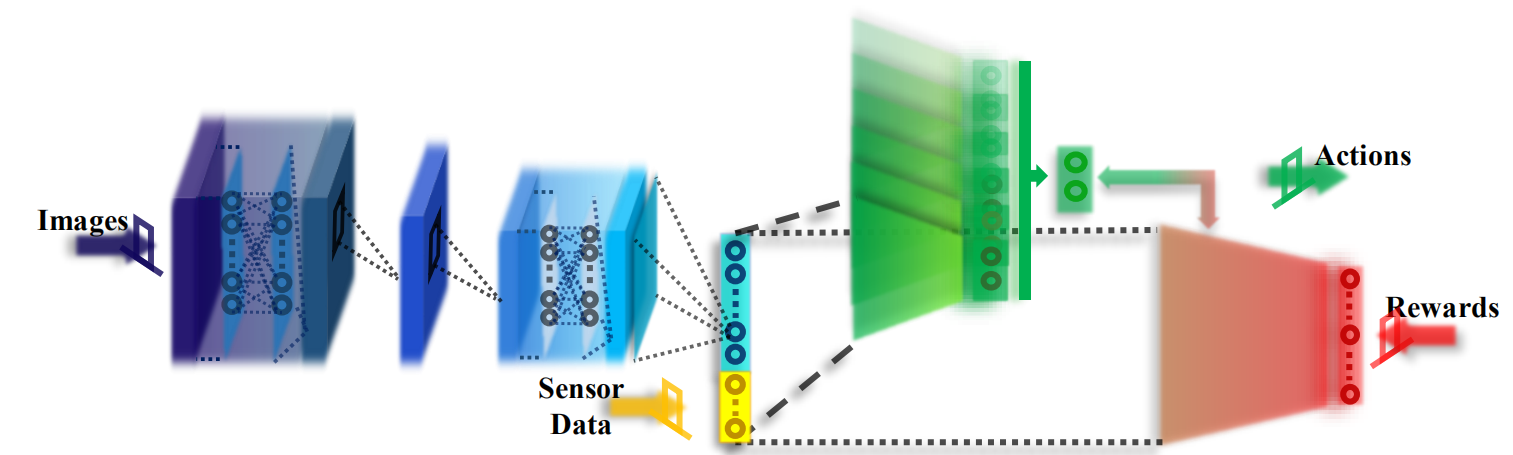
multi-DDPG是多Actor,单Critic的结构。也就意味着一个Critic要对所有的Actor打分。在Critic模型中,最后一个全连接层是非共享的,前面的部分都是对个Actor共享的。



